-
製品&サービス
- Customer Experience
マルチデバイスに対応したCMS、ヘッドレス対応と、先進機能を全て搭載し、フルマネージドクラウド上で動作する、10年連続No1※のCMS
企業の広報・宣伝・販促・営業活動における媒体のコンテンツ制作に関わるあらゆる情報を一元管理し、コンテンツ制作の生産性を向上
静止画を撮影し、360度のVR空間を構築出来るソリューション。安価に早くサービスを提供可能。ブラウザで閲覧できる3D-VR
- Digital Transformation
プロセスマイニングとタスクマイニングを最大限に活用。正確な現状分析と最適な解決手段を発見し、会社全体の最適化へつなげます。
見えなかった業務プロセスを自動的に一瞬で可視化
業務のタスクレベルでの活動を事実に基づき可視化
WindowsPC、MAC、Lunixどんな環境でも利用可能なRPA。大規模な運用にも耐えられる製品
- Data Base
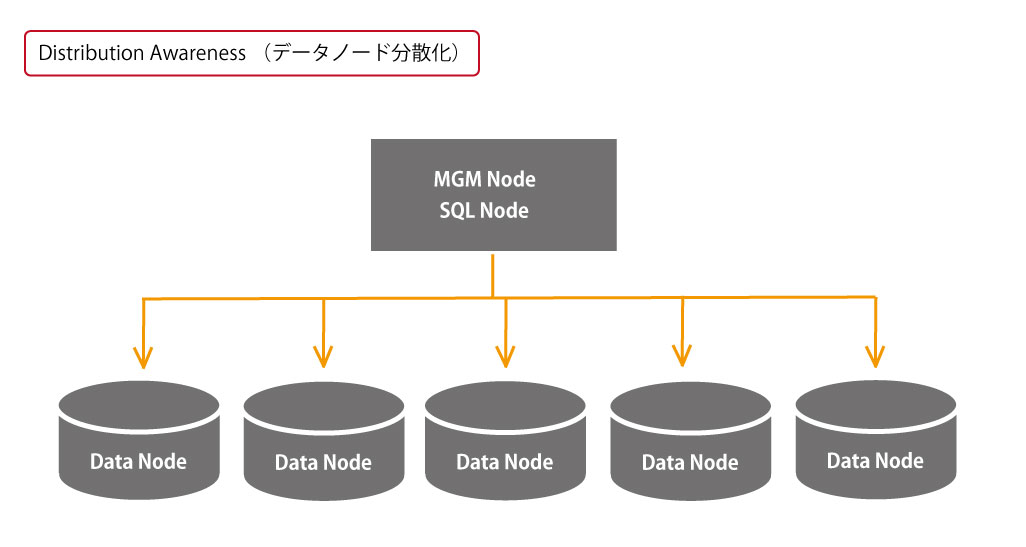
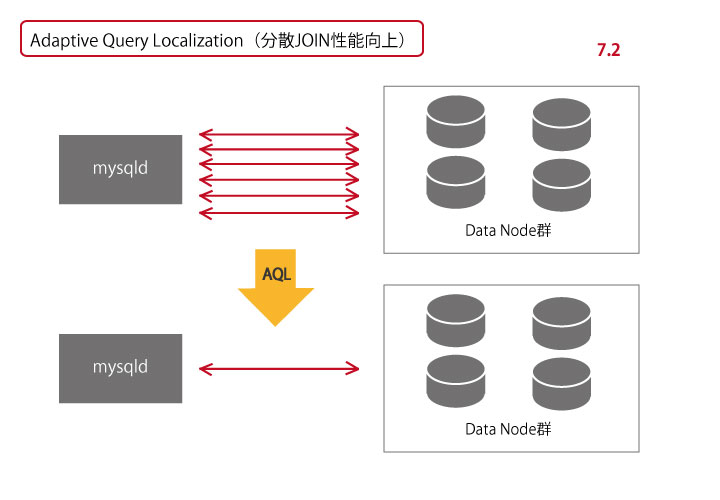
MariaDBは、MySQLの派生版として誕生したデータベース。レプリケーションの並列処理による性能向上、複数マスターによるレプリケーション、グローバルトランザクションIDの採用によるサーバーの柔軟な切り替えが可能
世界中の多くの企業が使用しているデータベース管理システムです。大容量のデータも高速に動作を行えるため、WEBサイト や検索エンジンでも多く使用されています。
- Service
Webサイト運用のあらゆる課題を解決。マーケティング戦略、SEO対策、UI/UX改善、セキュリティ強化など幅広い支援で、Web運用の課題を解決し企業のデジタル戦略を強化します。
- Customer Experience
- ソリューション
- イベント•セミナー
- ニュース&トピックス
- お客様事例
- 企業情報
-
 03-6409-6966
お問い合わせ
採用情報
03-6409-6966
お問い合わせ
採用情報
-
- English アクセス
-